By Ralph Gammon, Senior Analyst at Infosource
16 January 2025
1. Agentic AI Emerges as a complement to IDP:
Or maybe it’s the other way around, as Agentic AI is probably the macro piece here, but, either way, these two technologies go hand in hand, just like Capture and Workflow have for the past 40 years (dating back to FileNet’s original applications). For me, it has always been not a question of if, but when, AI would be applied to process automation. Similar to the way AI can learn to capture data from being fed examples of documents, it makes sense that AI can also learn to automate processes through a similar approach.
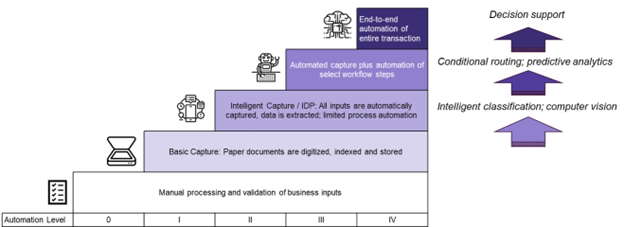
Five years ago, I remember having a conversation about this possibility with a leading workflow ISV. They agreed with the potential of the concept, but said it was just too hard to do at the time. As we wrapped up 2024, applying AI to workflow was probably still too hard, but extensive efforts are being made to introduce sophisticated reasoning and iterative planning (flexibility in mapping out a process) into LLMs, which should enable Agentic AI for process automation to become a reality. The incorporation of IDP as a sub-agent within these larger automations aligns with the most advanced level on Infosource’s Market Maturity Model (see graphic below)
2. Increasing Market opportunity around RAG creation:
Retrieval Augmented Generation (RAG) is being discussed as a key element for the success of Agentic AI. RAG is utilized to refine prompts being fed to LLMs to enable more focused outputs and reduce hallucinations. Early RAG models I’ve seen have been typically created out of corpuses of unstructured documents focused on a specific area of knowledge. This might be a list of regulations to help with a compliance application, for example.
To incorporate data from unstructured documents into a prompt, the documents need to be prepped and normalized. This can involve removing formatting, applying OCR, creating meta data, and separating out blocks of text into “chunks.” This output can then be stored in a vector database that can be accessed when needed by an agent. To give you an idea of the potential that analysts see for the use of RAGs, over the next five years the global vector database market is expected to more than triple in size.
In addition, in 2024, we saw San Francisco-based ISV Unstructured, which specializes in preparing unstructured content for ingestion by LLMs, raise $40M in a Series B round, with several notable investors including IBM, NVIDIA and the CEO of DataStax. According to the press release announcing the funding, “Unstructured is the first and only company that can ingest and pre-process all unstructured data into formats ready for use with foundation models.”
From my perspective, actions like document deconstruction and meta data extraction seem to be well within the realm of IDP software vendors. I had multiple conversations with IDP vendors at events in the latter half of 2024 about the potential of leveraging IDP for RAG model creation, but really haven’t seen too much in public forums aside from some posts by ABBYY and Hypatos. One interesting advantage that IDP vendors may have is their experience with meta data, which can potentially be prioritized to refine the accuracy of RAG-driven prompts even further.
3. The Emergence of Multi-Modal IDP Applications:
The idea of utilizing Capture & IDP software to process multi-modal input, including video, audio, SMS and other “non-document” files is something that Infosource has been promoting for years under the term “multi-channel” input. This feature has never received much traction in the market but last year, some vendors started discussing expanding their input sources to includes more than just documents.
Per the graph below, you can see that Infosource’s definition of Capture has always included (in the Business Inputs circle) video, photo, voice, SMS and other types of non-document files.
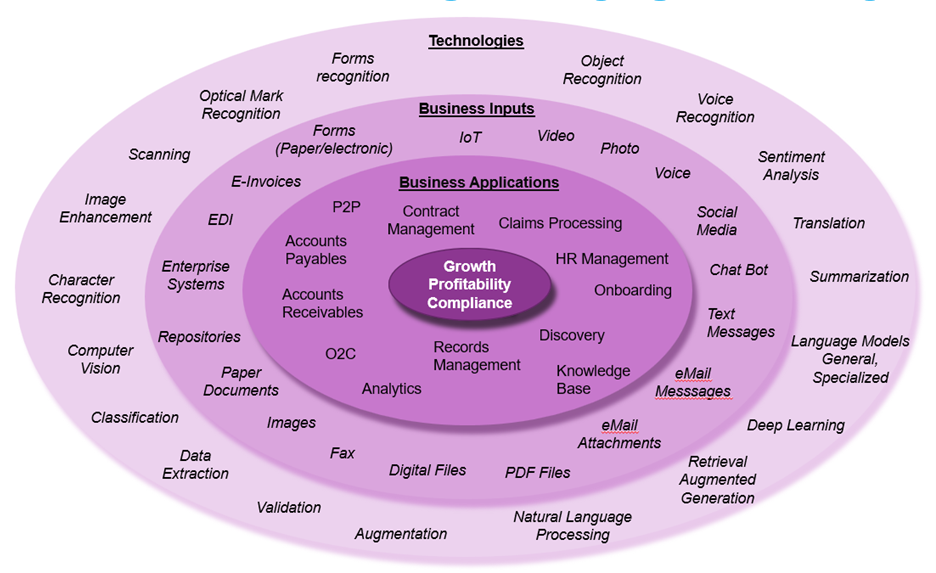
However, when we have queried Capture & IDP vendors historically, they have told us customer demand has always been focused almost entirely on different document formats. When AI was fully introduced into the Capture mix in the 20-teens, creating the IDP market, we thought this might open the door for a wider variety of input types, but, like OCR, the machine learning models being used were text focused. So were early LLMs, but at the same time they were being introduced, we also saw a slew of AI-based image generation models, often from the same vendors. It seems that these technologies are now finally coming together and the promise of true multi-modal processing technology for unstructured input is on the horizon. It will be interesting to see what the early applications will be but something around claims processing in property and casualty insurance seems like a good bet.